Bruno Postle <bruno@postle.net>
Authors note: this was originally going to be a technical specification, but I realised that the precise implementation is really not as interesting as the general concepts. If you are interested in the details, I suggest following the links and downloading the proof-of-concept code.
Introduction
This is a proposal born from many years frustration working with brain-dead CAD systems that seem to be designed with the vendor's interests in mind rather than the user's.
It's not just another open equivalent of an existing proprietary file format; this is a real attempt to draw on development methods and technologies pioneered in the world of Free Software, and apply them to the world of computer aided design and architecture.
I think that this proposal has tangible advantages over traditional approaches to computer aided design information, enough to make a real difference to the working practises of designers.
In essence, I want to be able to use the same techniques for designing buildings and managing CAD data that I use for software development. To do this, monolithic do-it-all file formats need to be abandoned in favour of a distributed collection of smaller, simpler files.
The guiding principle is that: If it can be a separate file, then that's what it should be.
This deconstruction process opens up a lot of possibilities, and quickly leads to the emergence of a whole series of features that were previously impractical or that had to be achieved with complex software solutions.
All this can be demonstrated with real code. You can download the “Draft” proof of concept application used to illustrate this document. This has now been updated to use a simpler Gui toolkit; it has a zooming and panning 2d display, but only supports two kinds of objects and one action – Editing is simply implemented by clicking and dragging to move.
Although the example tool is only 400 lines of Perl, all the features described below can be easily demonstrated with it.
Draft code on CPAN http://search.cpan.org/dist/Draft/

Fast efficient saving
The first and obvious result of storing “drawing elements” in discrete locations, is that stored data can be updated in-place without regenerating the entire data-set – Only the data that has changed or is new needs to be committed and written.
This has a series of ramifications:
Saving data is so quick that it is trivial to write changes to disk in real-time as they happen.
Changes are small and discrete, the host system can shutdown or fail without any data loss – Simply restart and continue.
There's no need for the user to remember to “save”, or wait while the software exports everything from memory to disk.
Fast efficient reading
The many files in a directory model is a very good fit with three existing technologies; a file-system that packs small files efficiently such as btrfs; Silicon Graphics' File Alteration Monitor, known as FAM or it's modern implementation called Gamin, and solid state ‘flash’ disks.
On a traditional file-system, small files consume a minimum fixed amount of disk space and so are very wasteful in large quantities, but with modern filesystems such as reiserfs and the more-recently developed btrfs this isn't a problem.
FAM simplifies data discovery. There is no need for an application to continually scan a file-system for new or modified files; FAM simply notifies the application quickly and efficiently – Even over Network File Systems.
On a spinning disk, with files scattered all over the surface, reading many files is potentially very slow (actually in real-world testing this wasn't too much of a problem, related files tend to be written together). Now with the arrival of solid state flash ‘disks’, random access of data is extremely fast and the advantage of serialising data to a single file on disk is not so clear.
Consequently:
The application can afford to update the display in real-time whenever something changes on disk.
Multiple processes can work on the same data simultaneously.
Multiple users can work on the same data and see each others work as it happens.
Extended object attributes (such as license information) can be left in the file and only read into memory when needed.
Note: It probably seems that reading thousands of separate files instead of one big file is going to be incredibly slow – At least for the initial read of a new drawing. I originally thought this would be a major drawback but, after testing it with real data, everything quickly ends-up cached in memory and there is very little performance penalty at all. For example: on my system, opening the large drawing (Figure 1.) takes 6 seconds, twice as fast as opening the equivalent DXF file in AutoCAD.
btrfs http://btrfs.wiki.kernel.org/
File Alteration Monitor http://oss.sgi.com/projects/fam/

Infinite undo
With every change being instantly written to disk, an undo system becomes essential. Fortunately, each change is just a simple discrete file-system modification and can be logged to a journal file allowing any change to be rolled back.
Undo and Redo are now implemented in Draft, use the Ctrl-z and Ctrl-y key combinations.
Straightaway, this gives advanced functionality: Undo is infinite and will even resume after a crash or reboot.
An alternative to implementing undo in the application itself is to manage it externally via the magicrcs daemon. In this case, Undo follows all changes, even if multiple applications and users have modified the data.
magicrcs http://search.cpan.org/author/JGLICK/SGI-FAM-1.002/magicrcs
Changes are easily encapsulated and portable
Two essential elements of this system are that: all data is stored in simple text-files, and that files on disk are not modified unless the contents themselves are modified.
This means that standard UNIX tools such as diff and patch can be used to encapsulate, transfer and apply change-sets.
Proposed changes can be placed in a patch file and submitted to maintainers.
Patches are human readable, trivial modifications can be approved by simply glancing over the file.
Patch files are typically applicable even when they are based on slightly differing sources.
diff http://www.gnu.org/software/diffutils/diffutils.html
patch http://www.gnu.org/software/patch/patch.html
Full version tagging and release management
A useful consequence of the file-format being extremely diff and patch friendly, is that it is also suitable for storage in Concurrent Versioning System (CVS) repositories (or a modern distributed alternative such as Git or Mercurial).
CVS can be server based, allowing network storage and access over the internet.
Versions and releases can be tagged for later retrieval; there is no need for elaborate renaming schemes, any version from any date can be retrieved precisely.
Read-only access can be granted, allowing others to follow design progress as it happens.
Multiple users in different localities can work on the same data.
CVS is quite fast enough for this level of usage. As an example, I created a repository with 11000 small files (local IDE DMA66 disk with ext3fs) and performed some typical CVS actions:
cvs -q import 90 seconds
cvs -q checkout 60 seconds
cvs -q commit 10 seconds
cvs -q update 3 seconds
CVS http://www.cvshome.org/
Git http://git-scm.com/
Mercurial http://www.selenic.com/mercurial/
Embedded resources are kept external
A drawing or model will probably include other resources, such as bitmaps or large areas of text.
Note: This isn't implemented in the example application.
Fine-grained permissions system
With a network world, drawings, models and designs are inevitably going to be assembled from different sources and different authors.
In addition to standard file-system arrangements such as per-file UNIX perms and access control lists, drawing elements can have embedded metadata such as Creative Commons licenses and copyright statements.
File permissions can be set so that two users can work on the same drawing at the same time, but be unable to modify each others data.
A drawing can be assembled from various sources, retaining full attributions – The copyright distribution status of the entirety would be easy to establish.
Creative Commons http://www.creativecommons.org/
Platform-independent data
This proposal isn't a plan for a single clever application, it's a scheme for an entire class of tools that inter-operate via a common file format.
To do this, the file-format needs to be easy to read by human beings, and easy to manipulate with text-oriented scripting tools.
A suitable tool it is going to leave the data on disk and only read and manipulate whatever subset it needs to be able to do it's job – No more and no less.
This is working with the philosophy of assembling many small tools that do a specific job well, rather than big monolithic tools that try to do everything, badly.
Object-oriented data
To be truly useful, a CAD file format needs to be extensible; every element, whether it's a simple line or a more complex assembly, needs to be truly object-oriented.
In this context, this means that the system needs to have the following properties:
So the basic unit of a drawing is the drawing itself; this is represented in the file-system as a directory or folder. Each element of the drawing; lines, circles, text or 3d solid, is a single text file within that directory.
Essentially, all drawings involve a certain amount of object reuse, it may just be a graphical symbol or a whole series of modular components that are used repeatedly.
Internal symbols and blocks can be created and used repeatedly. As subdirectories, they are moved whenever the parent drawing is moved.
External references are identical to internal ones except they are stored elsewhere on the file-system – They are not moved when the parent drawing is moved.
References can in turn reference other drawings or references.
To provide polymorphism, it is necessary that a reference has multiple inheritance and fine-grained overriding of any aspect of a referenced drawing.
The following 4 images demonstrate a full object-oriented system of inheritance, aggregation and polymorphism.
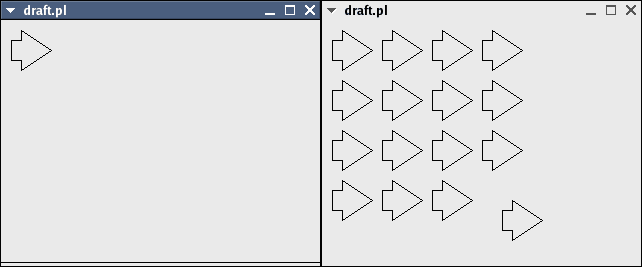
Figure 3. Left, a simple drawing. Right, a drawing that references the simple drawing 16 times.
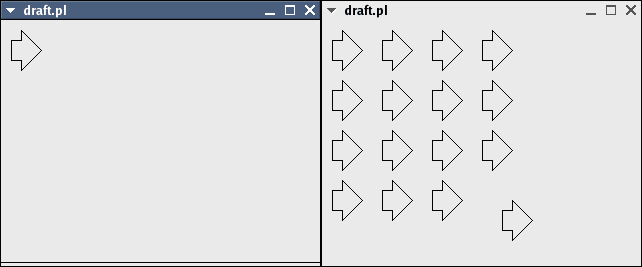
Figure 4. When a referenced drawing is modified, all instances of that object are instantly updated (note that the point of the arrow has been shortened).
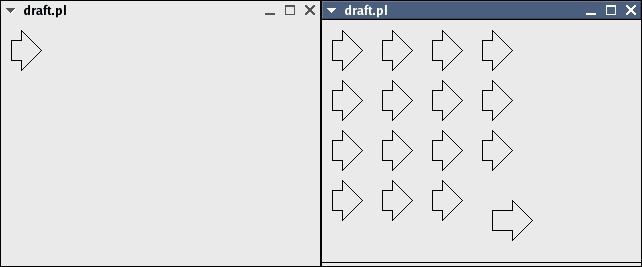
Figure 5. Parts of references can be overridden without any modifications to the original parent object (note that the stem of the bottom-right arrow has been lengthened).
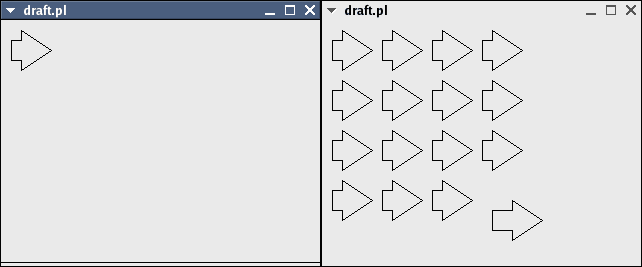
Figure 6. A modified reference can still inherit changes from the original object (note that the long-stemmed arrow gets the same changes as the other arrows).
Details
This isn't a full specification; for fine details of the implementation, I suggest downloading the proof of concept application.
Persistent names for all objects
Each object needs a key/name/filename, this should be unique and persistent through the lifetime of the object. Something like this:
HOSTNAME-UNIX_DATE-PID-INODE.SERIALISATION_FORMAT
Here's some examples:
celery-1045317918-1278-225423.eml
celery-1045317923-1278-42565.xml
celery-1045317957-1278-56488.yml
An automatically generated name should be provably unique, whereas a user generated name should be absolutely descriptive to prevent other people recreating the same object unnecessarily.
Some objects will need to be renamed so they can be remembered later:
enough-room-to-swing-a-cat.yml
Line-oriented data
So let's see one of these data files, internally they are serialised using YAML:
---
copyright:
- Jane Doe <jane@example.com>
license: http://creativecommons.org/licenses/sa/1.0/
points:
-
- 10
- 20
- 0
-
- 10
- 40
- 0
type: line
units: mm
version: draft1
Note that this is a simple, extensible, line-oriented text file format. An open file format needs to be quick and easy to parse and more importantly human readable.
A reference to a block/symbol might contain data like this:
---
copyright:
- Jane Doe <jane@example.com>
ignore:
- ../arrow.drawing/celery-1045317918-1278-225423.yml
license: http://creativecommons.org/licenses/sa/1.0/
location:
- ../arrow.drawing/
points:
-
- 170
- -130
- 0
type: reference
units: mm
version: draft1
That's it, there are more examples in the distribution tarball.
I'd like to hear any constructive comments, insights and suggestions for improvements to this document, you can add a comment below.
This document and proof-of-concept application was provoked by various rants concerning detail libraries, CVS, versioning & workflow, and an Open CAD file format on the Free Architecture mailing list.
Links
xSpace is almost exactly the same concept but implemented completely differently.
There is a Free and Open Geometry Data Standard wiki collecting together related information.
The CAD-linux-dev mailing list is the forum to discuss this development and similar ideas.
There is also a #cadfs IRC channel on irc.freenode.net.
Document changes
12 May 2009 Updated with btrfs and flash disk information
6 December 2005 Updated the internal file-format examples to YAML style as implemented in the current version
4 November 2005 Switched URL to http://bruno.postle.net/neatstuff/draft/ from http://bugbear.blackfish.org.uk/~bruno/draft/
7 October 2004 Added new 0.06 version with a sync() after each redo and undo
5 October 2004 Added new 0.05 version with journaling, redo and undo functionality
28 September 2004 Added new 0.04 version refactored to use YAML serialised data
29 February 2004 Added new 0.03 version that uses Tk::WorldCanvas instead of Gtk2
3 October 2003 Added new 0.02 tarball that includes pod documentation
6 September 2003 Fixed links
17 August 2003 Initial version
© 2003-2004 Bruno Postle <bruno@postle.net>